K8s Series - Chapter 1 Introduction to Kubernetes
In a world where microservice architecture is heavily adopted in building applications, Kubernetes is a wonderful out-of-the-box tool that assists in managing these containerised applications.
Kubernetes, known by some by the friendlier nickname k8s (pronounced Kates), is a container orchestrator. It ensures that:
- Containerised applications run where and when you want them to
- Available resources are allocated effectively
- System downtime is minimised
K8s comes with features that allow it to manage the running of containerised applications effectively. Namely:
-
Automated rollouts and rollbacks:
This feature allows incremental rollout of new changes to running applications while monitoring the overall system's health. If something goes wrong, K8s can automatically roll back the changes. This functionality is provided by the
Deploymentobject. -
Self-healing:
Kubernetes keeps track of the state of each node and pod. It automatically restarts containers that crash and replaces failed pods or nodes to maintain the desired system state.
-
Horizontal scaling:
Kubernetes offers the ability to easily scale applications based on resoure usage, such as CPU or memory utilisation, or even custome metrics.
-
Storage orchestration
Kubernetes supports a range of persistent and non-persistent data storage options, making it easy to mount storage systems of your choice.
-
Service discovery and load balancing
Kubernetes gives each Pod its own IP address and a single DNS for a set of Pods, enabling seamless communication between Pods and services within the cluster.
It also provides built-in load balancing, which distributes network traffic evenly across multiple nodes to maintain stability and performance.
-
Secret and configuration management
Kubernetes allows you to store Secrets and ConfigMaps separately from the Pods that use them, reducing the risk of exposing sensitive information in application configurations.
-
IPv4/IPv6 dual-stack
Kubernetes supports dual-stack networking, enabling both IPv4 and IPv6 addresses to be assigned and used simultaneously. This enhances network capability and scalability across different environments.
My K8s Dictionary
I have decided to maintain this section as a separate post, which can be found here - My K8s Dictionary
K8s Architecture
A k8s cluster comprises of two main components: Control Plane (Master Node) and Worker Nodes.
Pods are run on Worker Nodes.
The Control Plane manages the Worker Nodes and Pods within the cluster.

Image taken from the Kubernetes website.
Control Plane Node
Control Plane (Master) Node is the brain of the cluster, responsible for decision-making tasks.
Control plane components can be set up across multiple computers, but it is more common to configure all the components on the same machine, isolated from the Worker Nodes
The Control Plane manages the cluster through a combination of core components.
kube-apiserver
The kube-apiserver is the component that exposes the Kubernetes API to the "outside world". End users and cluster components communicate with the cluster via this API, often through a command-line tool such as kubectl
.
During request processing, the API server reads the cluster state from the key-value store (etcd), acts accordingly and updates the state if needed.
It is the only component that directly communicates with the etcd store, acting as the central interface for other Control Plane components that need to query or modify the cluster state.
kube-apiserver is designed to scale horizontally - multiple instances can run simultineously to handle increased load.
etcd
etcd is a distributed key-value store that holds and maintains the Kubernetes cluster's configuration data, state information, and metadata (E.g. namespaces)
etcd stores two key states: the desired state and the current state.
The controller mananger detects the discrepancies between these states and works to reconcile the differences.
kube-scheduler
As the name suggests, the kube-scheduler watches for newly created Pods and assigns them to available Nodes.
When deciding which Node to schedule a Pod on, the scheduler considers factors such as available resources (CPU, memory, etc), the cluster's overall health, and any defined constraints or affinity rules to select the most suitable Node.
The kube-scheduler runs each time a new Pod needs to be scheduled.
Custom scheduler can also be created.
kube-controller-manager
As mentioned earilier, one of the main roles of the controller manager is to ensure the cluster's current state matches its desired state and to maintain it that way. The controller manager retrieves the cluster state from the etcd via the kube-apiserver.
There are many types of controllers within a Kubernetes cluster, but they are combined into a single binary that is executed and managed by the kube-controller-manager in one process.
Some examples of controllers include:
- Node controller: Monitors the health and status of Nodes.
- Job controller: Watches Job objects and creates Pods to run them on Worker Nodes.
- EndpointSlice controller: Manages EndpointSlice Objects, which contain information about which Pods belong to which Service. When a Service of Pod changes, the EndpointSlice controller updates the corresponding EndpointSlice objects.
- ServiceAccount controller: Creates default service accounts for new namespaces.
Custom controllers can alse be developed.
cloud-controller-manager
The cloud-controller-manager acts a bridge between your cluster and your cloud provider's API. This allows the k8s core components to operate independently, while cloud providers integrate their functionality through plugins.
This component only exists when the cluster is running on a supported cloud provider. If the cluster is running locally (e.g. Minikube), this component does not exist.
The following controllers may have cloud provider dependencies:
- Node controller: Updates node-related information, such as marking Nodes or Pods as deleted when instances are removed.
- Route controller: Sets up networking routes that allow Pods on different Nodes to communicate.
- Service controller: Manages cloud provider load balancers for Kubernetes Services.
Worker Node
Pods are run on worker nodes.
A pod is the smallest deployable unit in k8s which comprises of one or more containers with shared storage, network resources and specifications on how they run.
A pod isn't usually created directly but via running workloads i.e. when Deployment or Job objects are used.
kubelet
Kubelet is a container manager that runs on each node, including the control plane node. It is responsible for managing and monitoring containers created by Kubernetes.
Kubelet does not manage containers started outside of k8s.
Its main job is to ensure that containers are running and healthy, according to the specifications defined in the PodSpec.
A PodSpec is a container manifest written in YAML or JSON format. When a Pod is created, its PodSpec is sent to the kube-apiserver, where it is validated and then stored in the etcd key-value store. Once stored, it can be accessed through the Kubernetes API.
There are other ways a container manifest can be passed to the kubelet such as:
- Sending a direct HTTP request to the kubelet's API endpoint.
- Passing the manifest file as a flag via the command line
The kubelet ensures that the containers in the Pods scheduled to its node are running and healthy by:
- Creating and deleting containers as needed
- Communicating with
etcdindirectly through thekube-apiserver - Collecting and reporting Pod status back to
kube-apiserver
Thekubelet's ultimate goal is to ensure the node's actual state matches the desired state defined in the PodSpec, keeping all containers on that node running as expected
kube-proxy (optional)
The kube-proxy also runs on every node in the cluster. It is responsible for implementing the Kubernetes Service abstraction by creating routing rules and directing network traffic between Pods, as well as between Pods and external clients.
It does this by:
- Gathering information about Services in the cluster and retrieving the corresponding Pod IPs and ports from the
kube-apiserver. - Monitoring for any changes to Services and Endpoints
- Creating or updating traffic routing rules when needed
A Kubernetes Service exposes a set of Pods to internal or external traffic by assigining them a stable IP address and DNS name.
The EndpointSlice controller maintains the list of Pod IP addresses that belong to each Service, while the Service controller manages the mapping between Service objects and their associated endpoints.
The kube-proxy component is optional if you use an alternative networking solution, such as Cilium, that handles service routing and load balancing on its own.
Container runtime
A container runtime is a low-level software responsible for creating and running containers on a node. Every node in a Kubernetes cluster must have one supported runtime installed, because the runtime is what actually pulls images, configures OS resources and start containers.
The container runtime handles the OS-level work required to bring containers to life. Its key responsibilities include:
- Pulling container images from registries.
- Prepare the container environment
- Creating and running containers
- Stopping and removing containers when instructed
Unlike the kubelet, the container runtime does not interact with the k8s control plane. It only receives instructions from the kubelet on the node.
Kubernetes supports Containter Runtime Interface (CRI) - compliant container runtime such as:
- containerd
- CRI-O
Kubernetes interacts with these runtimes via the CRI.
Kubelet vs. Container Runtime
Although both are involved in running containers, they operate at entirely different layers.
Kubelet - the Node Manager
- Receives PodSpecs from the API server
- Ensures the containers described in a Pod are running
- Performs liveness and readiness checks
- Reports Pod and node status back to the control plane
- Delegates actual container creation to the runtime
The Kubelet does not run the containers it self.
Container Runtime - The Worker
- Pulls container images
- Sets up the container's Linux environment
- Starts and stops containers
- Handles container-level operations requested by kubelet
It does not talk directly to the API server and only responds to the kubelet through the CRI
Summary
Kubelet decides what needs to be run and the runtime handles how it actually runs.
So what does the workflow look like, roughly?
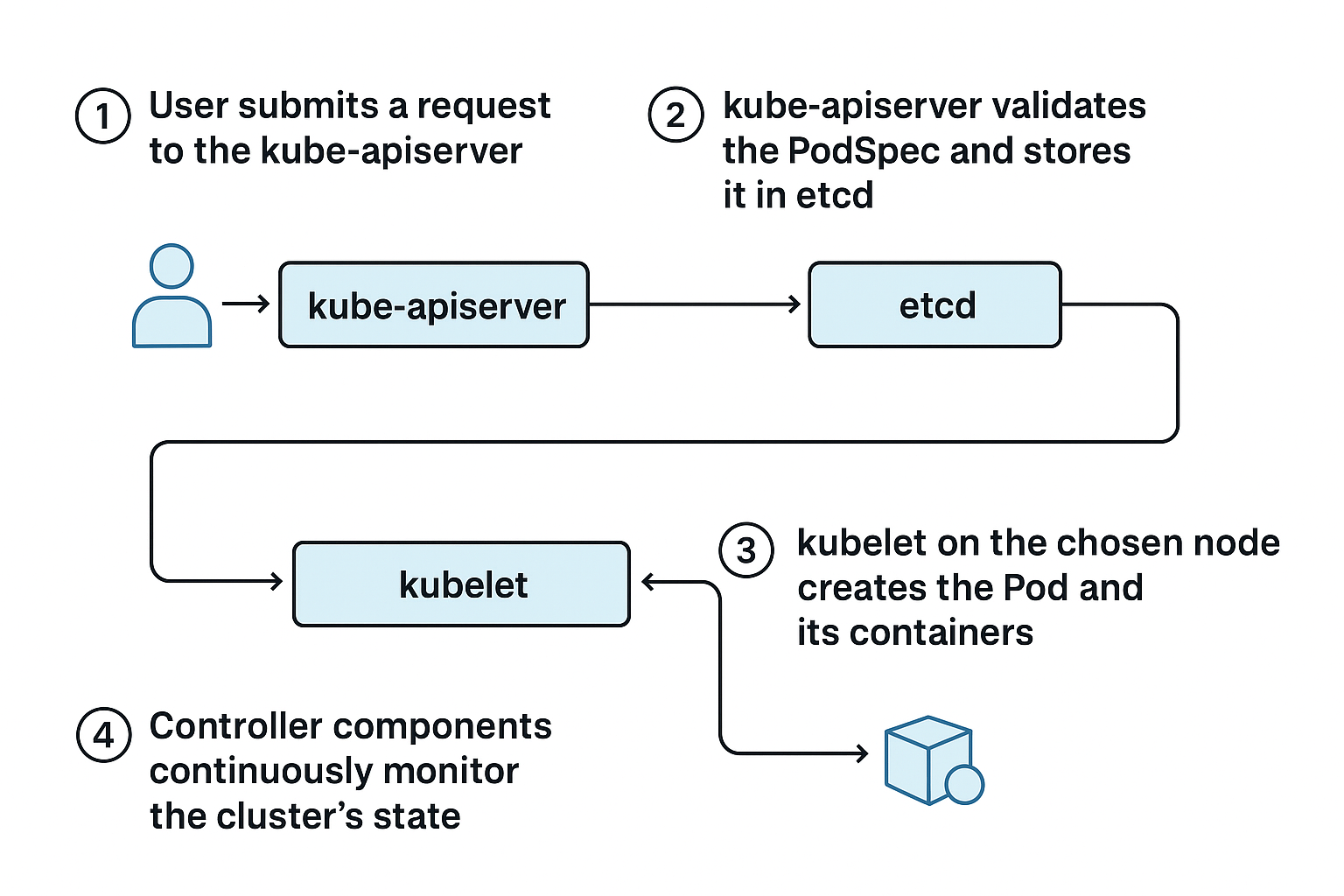
Scenario: A user has a multi-container application they want to run in a Kubernetes cluster. The workflow would look something like this:
- The user submits a request to the
kube-apiservervia a UI or command line tool such askubectl(which is installed separately) - The
kube-apiservervalidates the PodSpec and saves it inetcd. Once the Pod object exists, thekube-scheduler, which continuously watches the API server, identifies that the Pod has nonodeNameassigned. It selects a suitable node and writes a Binding back to the API server. Controllers such as the DeploymentController create ReplicaSets, and the ReplicaSetController creates the Pods that the scheduler selects. - The
kubeleton the selected node notices the Pod assigned to it by watching the API server. It retrieves the PodSpec and, through the Container Runtime Interface (CRI), instructs the container runtime (e.g., containerd or CRI-O) to pull the required images and start the containers. - Controller components continuously monitor the cluster's state. They read the actual state from the API server (which itself reads from
etcd). If a node fails, controllers initiate actions such as recreating Pods on a healthy node to maintain the desired state.
- ← Previous
My k8s dictionary - Next →
K8s Series - Chapter 2 Creating a Deployment